
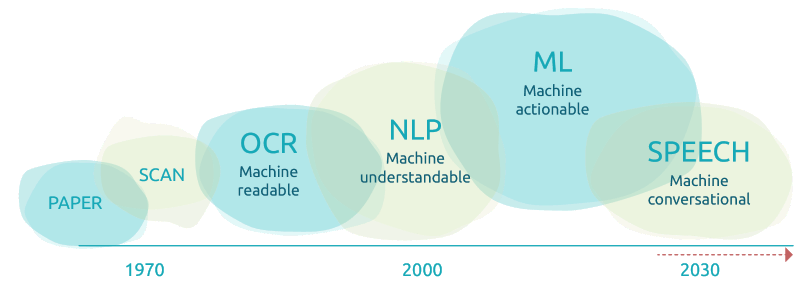
Seit den 1970er Jahren hat sich die Vorgangserfassung aus Dokumenten & Belegen rasant entwickelt.
OCR Anwendungen können dabei Inhalte lesen, aber erst durch den Einsatz von Machine Learning (ML) können Vorgänge wirklich automatisiert werden.
OCR Anwendungen (Optical Character Recognition) können in Verbindung mit einem Scan alphanumerische Zeichen aus Dokumenten und Belegen abbilden mit dem Ziel, diese maschinell weiter zu verarbeiten. OCR Anwendungen stellen damit eine Vorstufe zur Automatisierten Datenerfassung aus Dokumenten dar.
In jüngerer Zeit wird häufig der Begriff Intelligent Character Recognition (ICR) verwendet, bei dem zusätzlich die Analyse und Interpretation der gelesenen Inhalte erfolgt. OMR (Optical Marker Recognition) kann hingegen keine maschinengedruckten Zeichen erkennen, sondern erfasst in der Formularverarbeitung "Häkchen" oder "Kreuze".
Machine Learning additiv einsetzen für OCR
UIpath, Abbyy, Tesseract OCR: was einst mit dem Scannen von Büchern, Texterkennung und handgeschriebenen Ziffern begonnen hat ist heute zu einer typischen Aufgabe für die maschinelle Verarbeitung mit ML (Machine Learning) geworden. OCR Anwendungen wie UiPath, Abby und Tesseract sind auf die Texterfassung in Dokumenten spezialisiert. Kombiniert mit dem Machine Learning der AI Platform können Inhalte im grafischen Kontext (wo steht der Inhalt?) und inhaltlichen Kontext (was steht in unmittelbarer Nähe?) durch KI (Künstliche Intelligenz) automatisiert werden.

Template basierte OCR Erfassung
Template-basierte OCR Anwendungen können derart mit Regeln programmiert werden, dass sie an einer bestimmten Stelle im Dokument, in einem speziellen Textabschnitt oder hinter einem speziellen Begriff gefunden und gelesen werden können. Dabei muss jedes Fachdaten-Feld separat zugewiesen und konfiguriert werden.
Es fehlt an Struktur
Diese Konfiguration folgt einer engen Struktur. Sobald das Dokument oder der Inhalt sich leicht verändert, muss jeweils eine eigene Konfiguration gebildet werden. Und da selbst Rechnungen keiner festen Struktur folgen, sind die Extraktionsraten beim einfachen OCR Ansatz nicht skalierbar – können also nicht für die Bearbeitung großer Mengen von E-Mails und Dokumenten herangezogen werden. Sie führen zu erheblichen manuellen Nachaufwand.
OCR alleine ist unflexibel
Am Beispiel von Rechnungen wird bereits deutlich: sie benötigen Fachleute, die laufend Regeln zur OCR Dokumenterkennung anlegen und pflegen. Häufig widersprechen sich regeln, werden unübersichtlich, sind nicht optimierbar. Hier helfen kontextbasierte Lösungen – also die Kombination von OCR mit Machine Learning. Machine Learning-basierte OCR OCR kann kombiniert werden mit Robotic Process Automation (RPA) Software, einem Business Process Management (BPM) oder Workflow Tool. Entscheidend ist der additive Einsatz von KI (Künstlicher Intelligenz) in Form des Maschinellen Lernens.
Machine Learning-basierte OCR
OCR kann kombiniert werden mit Robotic Process Automation (RPA) Software, einem Business Process Management (BPM) oder Workflow Tool. Entscheidend ist der additive Einsatz von KI (Künstlicher Intelligenz) in Form des Maschinellen Lernens.
Schnelle Durchlaufzeiten, geringe Kosten, einfaches Training: KI-Anbieter wie ITyX setzen verschiedene Machine Learning Technologien im Prozess ein, um zuvor anhand trainierter Beispiele die Fachdaten zu extrahieren – und zwar ohne dass hierfür eine Position oder Regel zu konfigurieren wäre.
Schöne Nebeneffekte beim Einsatz von OCR und Machine Learning: sie benötigen weder technische Spezialisten noch dauernde Pflege. Schon mit 250 Beispielen je Vorgangskategorie erzielen sie Automatisierungs- und Extraktionsraten, die häufig jenseits von 80 % liegen – und innerhalb der ersten Wochen des Betriebs auf 95 % und mehr ausgebaut werden können.



